召回算法演进-1
召回,推荐系统的奠基者,拍脑袋的集大成者,业务效果的画线者。他决定了你最终能看到的内容的最大集合,他也决定了这次展示的业务体验。
假设你是一名推荐系统的开发工程师,经过了几天几夜的爆肝后,第一版的推荐算法终于上线了。这时候,产品找了过来,“不行啊,结果里没有最近上新的产品啊,会影响后续ROI的。老板要求必须有新品的。”你想反驳却又没办法,只能想办法在结果中尽量恰当的显示新品。但是怎么做呢?新品没有足够的行为数据,很难出现在最后的推荐结果中。正在一筹莫展的时候,旁边一个老员工给你除了个主意,“插一路新品的召回进去吧!”
没错,在推荐系统里召回的实践中,多路召回是常用的策略。也就是有多种不同的处理逻辑分别生成一路召回结果分别解决指定的一个问题,最后融合在一起作为召回结果。正因为这个原因,召回几乎称得上是推荐系统的流程中最丰富多彩的过程。
常见的召回算法通常分成非个性化召回和个性化召回两种,而在非个性化和个性化下面又有各种需求带来的不同算法。下面,我们按照在推荐系统的部署实现过程中,召回算法比较常见的上线过程进行一些常见召回算法的介绍。
非个性化召回
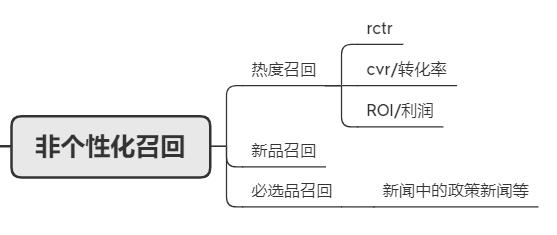
非个性化召回通常由策略组成,比如热度、新品、精品···,经常是为了保证业务性的策略而实现。这些方法大多不和用户的信息绑定。比如,现在的新闻信息流中,最top的几条通常是近期热点、时事、政策等,和用户无关,但是非常的重要。这些通过是通过人工或者某些既定的策略维护在一个制定的池子中,根据具体的需求情况进行展示。
1. 热度召回
第一种,也是在推荐系统前期上线的过程中最容易铺开的一种,热度召回算法。
这种召回算法实质上是一个存储在实时数据库中的倒排索引。这里倒排索引的value是待筛选的商品ids,key则是召回过程中需要使用到的索引query。其中倒排索引的value中的商品按照当前要求的热度召回指标的顺序从高到低进行排序,排序的结果就是在这一路召回中需要的顺序。

热度召回算法的思路很简单,就是按照当前的需求指标对商品进行简单的排序筛选,将满足筛选条件的商品集合进行召回展示。实现过程很简单,直接使用一定时间窗内的商品指标的统计结果即可。以ctr指标为例,对应的统计指标通常如下:
$$
\begin{align}
ctr &= \frac{click_cnt}{expose_cnt} \tag{1}\\
corr_ctr &= \frac{click_cnt + corr_click_cnt}{expose_cnt + corr_expose_cnt} \tag{2}\\
corr_ctr_2 &= weight_1 * hour_1(corr_ctr) + weight_2 * hour_2(corr_ctr) + \dots \tag{3}
\end{align}
$$
如上,针对最基础的ctr统计方法有两种优化策略。
第二种相对第一种主要解决了新品因为曝光量少而存在的商品ctr统计值存在一些偏差的问题,通过分子分母的校验,保证新品或者是曝光量较少的商品的统计ctr指标能够保持在一个比较稳定的位置上,而不会因为统计偏差导致倒排列表的前面被大量的新品或曝光量少的商品占据,而挤压了真正优质的商品的存活空间。
第三种方法通过时间衰减的策略,保证了热度召回的策略对实时热度商品的快速反应,能够保证在最近一段时间内出现爆款的商品可以较好的出现在召回商品中,而不容易被前期的结果影响。同时这种策略可以对新品和上线时间较长但因为质量不佳而曝光量较少的商品进行一些区分。
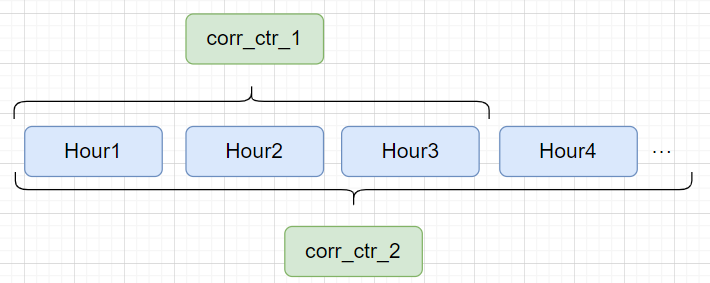
常见的热度召回除了以ctr为排序指标外,还可以使用cvr等深层指标进行排序从而实现针对不同质量商品的过滤逻辑。
2. 其他用途
同样,可以通过调整不同的倒排指标实现对召回商品的质量调整,常用的召回通道如下:
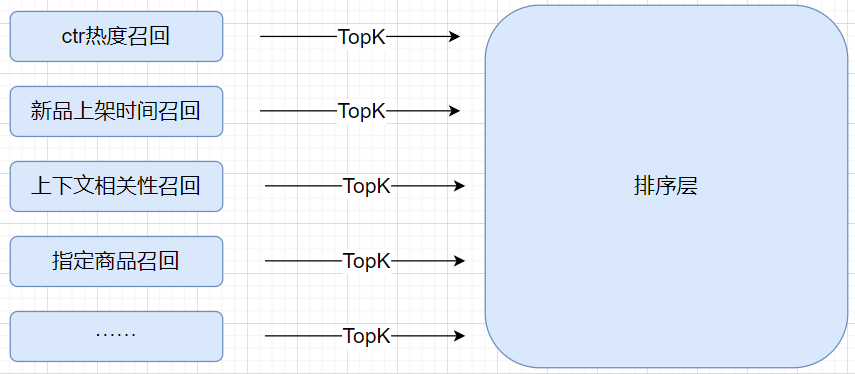
新品上架时间召回:将商品按照上架时间进行倒排,主要为了解决新品因为没有足量的行为数据,导致在排序层较难获得曝光机会的问题。
上下文相关性召回:主要使用在搜索场景或者是相关性推荐场景上。
指定商品召回:主要是为了除了一些拥有特权的商品的召回,尤其是在新闻场景下,某些特殊新闻的召回需求。